A blog post from BEA Director Vipin Arora
I wouldn’t imagine the phrase “data quality” stirs the imagination of many people. I get it. Artificial intelligence or big data—or even e-commerce, to take it back a few years—sound more exciting. Our team at BEA, however, gets fired up about data quality, especially improving data quality. That’s great, you might be thinking, but what exactly do you mean by data quality?
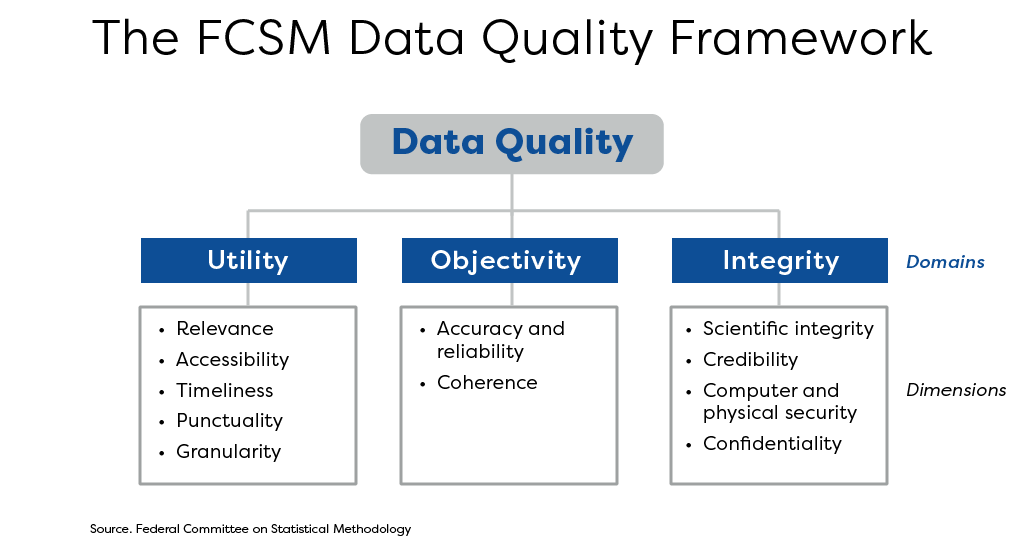
It’s not a simple question. To my knowledge, statisticians around the world have yet to agree on a common definition. In the United States, however, we seem to be converging on a framework. This framework for data quality was developed by the U.S. Federal Committee on Statistical Methodology (FCSM), a group of senior statisticians from across the federal government. Their framework is the best way I’ve come across to think about data quality.
The FCSM framework is so powerful because it’s comprehensive and intuitive. At the highest level, it has three broad categories (what they call domains): utility, objectivity, and integrity. Loosely you might think of these as usefulness, accuracy, and adherence to standards. We might stop there, but the framework offers more detail for those who want to go deeper.
Each of the three broad categories has subcategories (what they call dimensions). For example, timeliness and granularity are two of the dimensions of utility. Similarly, accuracy and reliability together are part of objectivity, while security and confidentiality are dimensions of integrity. As I said earlier, the framework is both comprehensive and intuitive.
That brings me back to BEA and our continual pursuit of better data quality. As many of you are aware, we have a long history of innovation that leads to better statistics. We’ll continue that tradition this year by again making significant improvements to data quality—especially timeliness and granularity.
I’d say that’s something to get excited about.